
Data engineering has always been the unglamorous backbone of every data-driven organisation. It is the discipline of getting data from where it lives to where decisions get made — reliably, accurately, and at scale. For years, that meant stitching together ETL scripts, cron jobs, monitoring dashboards, and a small army of engineers to babysit the whole thing.
That model is breaking. Not because data volumes have grown (they have), but because the nature of what organisations need from their data has changed. Boards want real-time answers. Operations teams want automated alerts. Finance wants forecasts that update themselves. The old pipeline-and-dashboard model produces reports. Organisations now need systems that think, decide, and act.
That is exactly what AI agents in data engineering deliver.
This guide covers what AI agents actually do inside data engineering workflows, 12 proven use cases drawn from real production deployments across industries, the results organisations are seeing, and what to look for when evaluating a platform.
What Is an AI Agent in Data Engineering?
An AI agent in data engineering is an autonomous software system that can perceive data in its environment, reason over it, and take action — without a human issuing instructions for each step.
Unlike traditional automation (scripts that run on a fixed schedule) or RPA (bots that mimic human clicks), an AI agent can handle variability. It can interpret an anomalous reading and decide whether to alert, investigate, or self-correct. It can receive a natural language question and determine which data sources to query, in which order, before returning a governed answer. It can monitor hundreds of data streams simultaneously and surface the signal that matters.
The distinction matters in data engineering because data is inherently messy and contextual. A script that runs at 2am does not know that a public holiday has made today's sales data look like an anomaly. An AI agent, given the right context, does.
How AI agents differ from traditional data tooling:
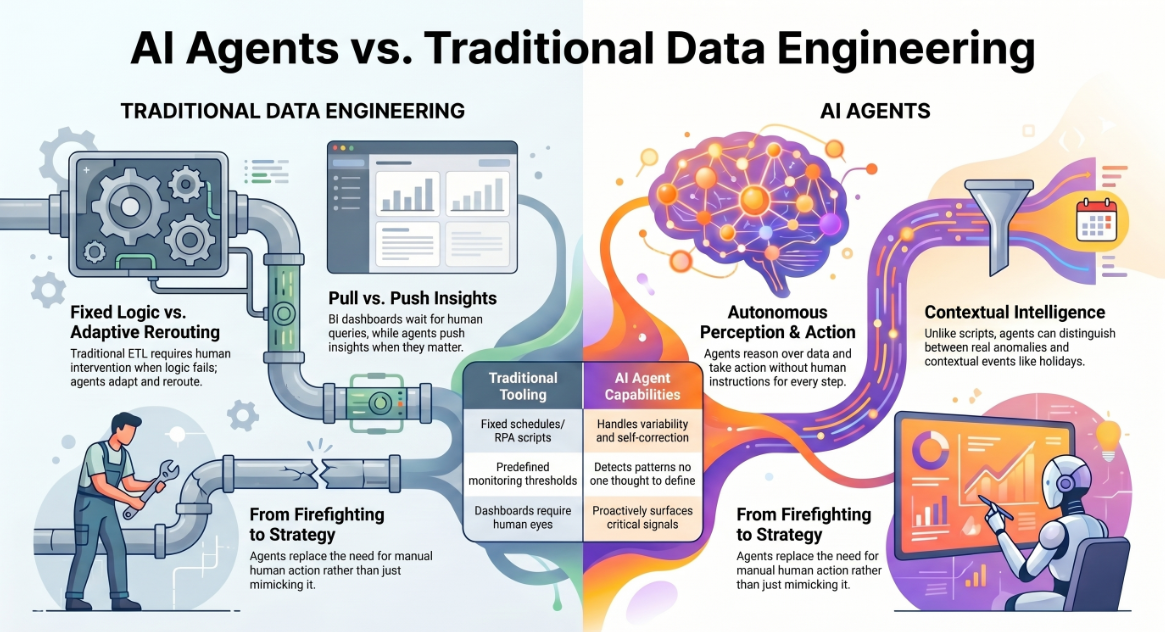
- Traditional ETL pipelines follow fixed logic and require human intervention when something unexpected happens. AI agents can adapt, reroute, and escalate.
- Traditional BI dashboards surface data when a human looks. AI agents push insights when something matters.
- Traditional monitoring tools alert on predefined thresholds. AI agents detect patterns that no one thought to predefine.
- Traditional RPA replicates human actions. AI agents replace the need for a human action in the first place.
The result is a fundamentally different relationship between data teams and data systems — less firefighting, more strategy.
Why Data Engineering Is the Highest-Leverage Starting Point for AI Agents
Most organisations begin their agentic AI journey in customer-facing applications — chatbots, support agents, voice assistants. These are visible wins, but their impact is relatively contained.
Data engineering sits underneath everything. When you deploy AI agents at the data layer, every downstream team benefits: operations get faster alerts, finance gets more accurate forecasts, leadership gets better decisions, and commercial teams move faster on market signals.
The numbers from early enterprise deployments support this. <a href="https://www.netcomlearning.com/blog/ai-agents-for-data-engineering-data-science">Organisations implementing AI agents for data engineering report an average of 40% faster pipeline development</a>, with data quality incidents dropping by 70% or more in many cases. Gartner projects that by 2028, 33% of enterprise software applications will include agentic AI — up from less than 1% in 2024.
The leverage is structural. Fix the data layer with agents, and every function of the business runs on better information.
12 Proven AI Agent Use Cases in Data Engineering
The following use cases are drawn from real production deployments across industries including retail, logistics, energy, finance, healthcare, real estate, and hospitality. Outcomes referenced are from those deployments.
1. Automated Data Pipeline Monitoring and Anomaly Detection
One of the most immediate and high-value applications of AI agents in data engineering is continuous pipeline monitoring. Traditional approaches require engineers to write monitoring rules in advance — thresholds, expected ranges, alert conditions. When something unexpected happens that no one anticipated, the system stays silent until someone notices the downstream damage.
AI agents approach this differently. They learn the normal behaviour of a pipeline over time — typical volumes, timing patterns, value distributions — and flag deviations that fall outside expected ranges, even if those ranges were never explicitly defined.
In one deployment for a state power transmission utility, AI agents were applied to transmission data ingestion and operational dashboards. The result was faster identification of grid exceptions and operational risks, improved reliability through proactive monitoring, and better operational transparency for leadership — replacing reactive reporting with continuous intelligence.
A campus-scale research institute deployed a similar approach for energy management, with agents monitoring sensor data, detecting inefficiencies, and issuing proactive forecasting alerts. The outcome: improved energy visibility, reduced manual monitoring effort, and more predictable operations.
What this use case requires: A stable data ingestion layer, historical pipeline data to establish baselines, and an agent framework that can trigger alerts and handoffs without human intervention.
2. Agentic ETL and Data Ingestion Workflows
Traditional ETL is brittle. Schema changes upstream break pipelines downstream. New data sources require manual integration work. Format inconsistencies require engineer time to investigate and resolve.
AI agents make ETL more resilient by handling variability at the ingestion stage. Vision-LLM capabilities allow agents to extract structured data from complex, unstructured sources — PDFs, images, mixed-format documents — without requiring a new integration for each format.
In one deployment for a commercial works business, a multi-agent orchestration workbench was built to handle tender document ingestion. Agents handled retrieval, workflow determination, revision analysis, and extraction from complex PDFs — with deep system integration, quote locking, and full audit logs. The result: up to 90% faster tender document processing, a 95% extraction accuracy target for standard formats, and dramatically reduced bid risk through revision and change detection.
In another deployment for a global pharma sourcing platform marketing over 7,500 SKUs, agents automated RFQ processes, supplier matching, and procurement decision support — with analytics on price, lead time, and vendor performance. The outcome was faster procurement cycles, reduced vendor coordination overhead, and better sourcing competitiveness.
What this use case requires: Document AI or vision-LLM capability, integration with core operational systems, and governance controls to handle exceptions and approvals.
3. Natural Language Querying Over Enterprise Data
One of the most persistently frustrating bottlenecks in enterprise data operations is the queue. Business stakeholders have questions. Data teams have limited capacity. By the time an analyst has pulled a report, the window for the decision has often closed.
AI agents with natural language query (NLQ) capability remove this bottleneck entirely. A business user asks a question in plain language — "What were our top three underperforming product categories last month, and what drove the variance?" — and an agent queries the relevant data sources, applies semantic governance to ensure consistent metric definitions, and returns a governed answer.
This is not a chatbot on top of a spreadsheet. A properly built NLQ data agent understands business context, enforces access controls, explains its reasoning, and can escalate to a human when confidence is low.
In one deployment for a Silicon Valley analytics startup, an agentic data analytics layer was built to deliver self-serve, governed answers through natural language. The outcome was faster strategic visibility without BI queueing, improved alignment through consistent metric definitions, and scalable insight access across teams.
A privately-held retail holding company deployed a similar context engine — combining structured and unstructured data sources under a semantic governance layer — allowing leadership to move from insight to action quickly across functions and systems.
What this use case requires: A semantic layer that maps business terms to data definitions, a governed query engine, and role-based access controls baked into the agent layer.
4. Cross-System Analytics Consolidation
Multi-entity organisations — holding groups, multinational operators, franchise networks — face a chronic data problem: every business unit measures things differently. KPI definitions vary. Reporting cadences don't align. Leadership spends more time reconciling numbers than acting on them.
AI agents solve this by sitting above the existing system landscape and applying standardisation logic at the query and output layer — without requiring every underlying system to be rebuilt or migrated.
In one deployment for a global logistics and warehousing business operating across India, the UK, Europe, and the US, analytics consolidation was delivered across multi-entity global operations. The outcome was a single operational view across entities, faster leadership reporting and issue identification, and improved consistency of operational metrics.
A large family business group comprising over 30 companies deployed an automated procurement and finance KPI alert system across group entities — standardising margin control, vendor performance, and working capital intelligence across the portfolio. Early detection of margin erosion and vendor slippage became automated, replacing manual variance surprises with continuous monitoring.
What this use case requires: A unified context engine capable of ingesting structured data from multiple systems, a semantic governance layer for consistent definitions, and scheduled or triggered reporting for leadership.
5. AI Agents for Competitive and Market Data Monitoring
Competitive intelligence has traditionally been a manual, periodic activity — analysts checking competitor websites, compiling price lists, summarising market movements. This produces snapshots. Modern businesses need continuous signals.
AI agents replace manual monitoring with always-on intelligence. They ingest data from e-commerce platforms, pricing portals, third-party sources, and public channels, then surface gaps, threats, and opportunities as they emerge — not at the next monthly review.
In one deployment for a major HVAC manufacturer competing in a highly price-sensitive market, AI agents were deployed for continuous e-commerce and channel monitoring — tracking pricing, MRP, discounts, offers, availability, and ratings. Agentic Q&A was mapped to leadership questions, with analytics views for pricing gaps, threats, and portfolio movement. The outcome: faster competitive response cycles, earlier identification of pricing gaps and promotional shifts, and always-on monitoring replacing manual checks across portals.
A stock market research platform deployed agents for data ingestion, indicator pipelines, research automation, and insight generation — with alerts and thematic dashboards replacing manual analyst workflows.
What this use case requires: Data ingestion from web and third-party sources, configurable monitoring rules, and a Q&A layer that maps signals to leadership questions.
6. Smart Grid and Energy Data Operations
Energy and utility operations generate enormous volumes of sensor, operational, and performance data — most of which goes unanalysed because the volume exceeds what human teams can process. The result is reactive operations: incidents are discovered after they have already caused damage.
AI agents shift energy data operations from reactive to predictive. They ingest sensor and utility data continuously, detect anomalies before they become incidents, generate forecasts, and trigger automated alerts and workflow routing for field resolution.
In one smart grid deployment, agents were built on top of existing utility systems to deliver agentic analytics and automated operational alerting. The outcome was higher operational visibility across grid operations, faster exception detection and response coordination, and more proactive grid operations through continuous monitoring — replacing periodic manual reviews with always-on intelligence.
A campus research institute applied a similar approach to energy management — monitoring, forecasting, and optimising campus energy consumption with agents that detected inefficiencies and issued early alerts before they affected operations.
What this use case requires: Sensor or SCADA data ingestion capability, anomaly detection models that learn from historical patterns, and integration with field operations workflows for alert routing.

7. Retail Inventory Intelligence and Demand Signals
Retail data engineering faces a specific challenge: the data volume is enormous, the time windows for action are short, and the cost of being wrong — stockouts, overstock, missed promotions — is immediately visible in revenue.
AI agents applied to retail data can track inventory levels, pricing, promotional performance, and customer behaviour across stores or channels in real time, surfacing exceptions and opportunities before they become problems.
In one deployment for a national retail chain with over 700 stores, an inventory intelligence agent was built to give store-level pricing, stock, and promotions visibility. A knowledge and training agent gave on-demand access to POS and SOP documentation. A conversational analytics layer answered business queries instantly. The outcome was a reduction in manual helpdesk burden, improved store-level inventory visibility, faster onboarding through on-demand training guidance, and shorter analysis cycles for recurring business questions.
What this use case requires: Real-time data ingestion from POS, inventory, and promotions systems, a semantic layer that understands retail-specific KPIs, and a governed interface for store operations teams.
8. Supply Chain and Logistics Data Orchestration
Supply chains produce data across terminals, warehouses, transport legs, and third-party partners — data that is rarely unified, often delayed, and formatted differently at each node. The resulting visibility gap is one of the largest sources of operational cost in enterprise logistics.
AI agents address this by digitising and orchestrating data across the supply chain, building exception management into the data layer itself, and surfacing the right signals to the right people at the right time.
In one deployment for a global ports and logistics operator — one reporting record revenues of $20 billion in FY2024 — a terminal and rail management solution was built to digitise and optimise port-to-inland logistics operations. Rail scheduling, yard visibility, exception management, and executive dashboards were all delivered as part of the solution. The outcome was improved operational visibility and exception response, higher predictability of terminal-to-rail throughput, and more efficient coordination across terminal and inland logistics.
What this use case requires: Integration with terminal management, WMS, and transport systems; real-time visibility layers; and exception management logic that routes the right alert to the right team.
9. Finance and Banking Data Automation
Financial services data engineering carries unique requirements: regulatory auditability, data lineage for compliance, and the need for decisions that can be explained and justified after the fact. These requirements make AI agents particularly valuable — and particularly constrained.
Done well, agents in financial data workflows handle omnichannel intake, route cases to the appropriate workflow, generate next-best-action recommendations, and maintain full audit trails throughout.
In one deployment for a global fintech provider serving banks and credit unions, omnichannel AI agents were built for banking support with fully auditable workflow automation. The solution covered chat, email, and phone intake, agent-assist summarisation, next-best-action recommendations, and full auditability and SLA monitoring. The outcome was faster case handling, improved consistency, reduced operational load through automation, and better compliance readiness via audit trails.
An AI CFO agent deployed for a growing business platform delivered continuous cashflow insight, forecasting, and actionable finance guidance — with portfolio views for advisors managing multiple clients, early detection of runway risks, and forecast and scenario modelling agents running continuously.
What this use case requires: Omnichannel data ingestion, strict audit log capability, integration with core banking or finance systems, and governance frameworks that meet regulatory standards.
10. Document and Tender Data Extraction (Vision-LLM)
Unstructured documents — contracts, tenders, invoices, regulatory filings, supplier quotes — represent some of the most valuable data in any organisation, and some of the hardest to operationalise. Extracting structured, actionable information from complex PDFs has historically required manual review.
Vision-LLM agents change this. They can read documents with complex layouts, extract structured fields with high accuracy, cross-reference against existing system data, and flag discrepancies or missing information before the document reaches a human reviewer.
In one deployment using an Intelligent Document Workbench with multi-agent orchestration, the process covered tender retrieval, workflow determination, revision analysis, and vision-LLM extraction from complex PDFs — all integrated deeply with operational systems, with quote locking and audit logs. The engineered target was up to 90% faster document processing and approximately 95% extraction accuracy for standard formats.
A tax technology platform applied the same principle to cross-border transaction screening — automated source collection, summarisation, and drafting support with citations — replacing manual source-hunting with an AI-led research workflow.
What this use case requires: Vision-LLM capability for layout-aware document understanding, structured output validation, system integration for automated data entry, and exception routing for human review.
11. Insights-to-Action: Agents That Turn Dashboard Data Into Tasks
Dashboards are passive. They require a human to look at them, interpret them, decide what to do, and then go do it. At scale, this creates a bottleneck: the data is available, but the action is delayed by human bandwidth.
Insights-to-action agents close this loop. They sit on top of existing dashboards and data systems, apply governed rules and decision logic, and trigger tasks, alerts, or workflow actions automatically — without waiting for a human to notice the signal.
In one deployment, an agentic data analysis layer was built on top of existing dashboards for a retail holding business, converting insights into governed, auditable actions and tasks. The outcome was a shift from reactive reporting to proactive execution loops, standardised decision logic across teams, and automated task creation and completion tracking.
An enterprise sales operation deployed an always-on account monitoring agent — capturing signals, running opportunity identification logic, and routing follow-up tasks to CRM systems, with pipeline hygiene and leadership dashboards updated automatically. The outcome was higher account coverage without increasing headcount, faster response cycles on opportunities and renewals, and more consistent execution across the sales team.
What this use case requires: Integration with existing dashboards or data platforms, a rules and governance layer for decision logic, and task routing capability that connects to downstream operational systems.
12. Stock Market Data Science and Research Automation
Financial markets research is data-intensive, time-sensitive, and highly repetitive at the ingestion and analysis stage — all characteristics that make it well-suited for agent automation.
AI agents in this context handle data ingestion and indicator pipelines, run research workflows automatically, generate alerts and insight summaries, and allow analysts to spend their time on higher-order interpretation rather than data wrangling.
In one deployment for a market research and technical analysis platform using Elliott Wave theory and related indicators, agents were built for data ingestion, indicator pipelines, research automation, and insight generation — with alerts and thematic dashboards delivering the output. The outcome was faster production of market insight packs, more repeatable and consistent research workflows, and better signal visibility through automated analytics.
What this use case requires: Market data ingestion from relevant sources, configurable indicator and signal pipelines, and a delivery layer that formats outputs for analyst or client consumption.
What Results Are Organisations Actually Seeing?
Across the deployments described above, several consistent outcome themes emerge:
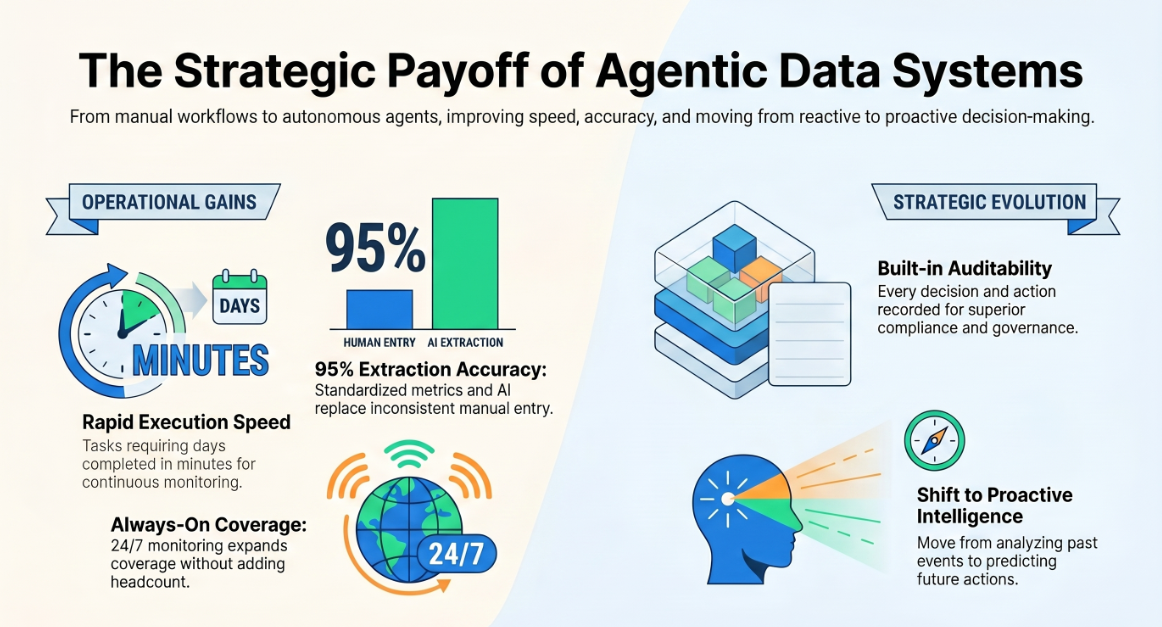
Speed. Tasks that previously required hours or days of analyst or engineer time are completed in minutes. Competitive monitoring that was done weekly becomes continuous. Tender processing that took days approaches hours. Procurement cycles shorten.
Accuracy. Removing manual steps removes manual error. Extraction accuracy targets of approximately 95% replace the inconsistency of human data entry. Metric definitions become standardised rather than contested.
Coverage. AI agents do not get tired or go on holiday. Always-on monitoring replaces periodic checks. Account coverage expands without adding headcount. Competitive signals that used to be missed are now captured.
Auditability. A well-built agentic data system creates a record of every decision, query, and action — a compliance and governance asset that manual processes cannot match.
Shift from reactive to proactive. The most consistent outcome across deployments is a structural change in how organisations relate to their data: from finding out what happened to being told what is about to happen, and what to do about it.
AI Agents vs Traditional BI and RPA: What's the Difference?
This question comes up consistently in enterprise evaluations. Here is a clear breakdown:
Traditional BI (Tableau, Power BI, Looker): Surfaces historical data in dashboards. Requires a human to look at it. Cannot take action. Excellent for structured exploration; poor for real-time operational response.
RPA (UiPath, Automation Anywhere): Automates defined, rule-based sequences of human actions. Brittle when inputs change. Requires explicit instruction for every scenario. Cannot reason.
AI agents: Perceive context, reason over it, and act. Handle variability. Learn from outcomes. Can be given goals rather than instructions. Integrate across systems. Generate auditability automatically.
The practical implication: RPA is the right tool when the process never changes. AI agents are the right tool when the world is messy — which describes most real data engineering environments.
What to Look for in an AI Agent Platform for Data Engineering
Not all AI agent platforms are built for enterprise data environments. When evaluating options, the following capabilities are essential:
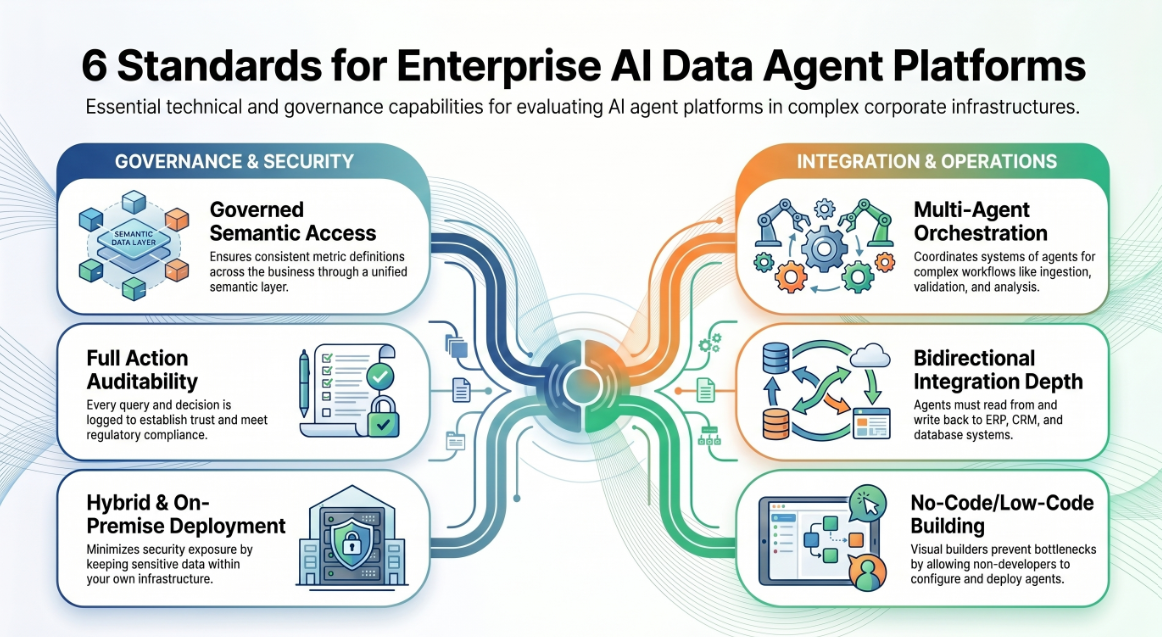
Governed access and semantic layer. The agent must understand your data in business terms, not just technical ones. A semantic governance layer ensures that when different parts of the business ask the same question, they get the same answer — based on consistent, governed metric definitions.
Auditability. Every query, decision, and action the agent takes should be logged. In regulated industries, this is non-negotiable. In all industries, it is the foundation of trust.
On-premise and hybrid deployment. Enterprise data is sensitive. A platform that requires all data to leave your infrastructure creates security and compliance exposure. Look for options that can run on your own infrastructure, on your terms.
Multi-agent orchestration. Complex data workflows are not single-step. They involve multiple agents handling different tasks — ingestion, validation, enrichment, analysis, delivery — coordinating as a system. A platform that only supports single-agent workflows will hit a ceiling quickly.
Integration depth. The value of a data agent is proportional to the systems it can reach. Look for platforms with broad integration capability — ERP, CRM, WMS, databases, APIs — and the ability to write back to systems, not just read from them.
No-code and low-code agent building. Data engineering teams are not all developers. A platform that requires coding for every agent configuration creates a bottleneck. Look for visual workflow builders and no-code agent configuration alongside developer-grade extensibility.
assistents.ai's Agentic Business Intelligence product was built with all of these requirements in mind — natural language querying over enterprise data, governed access, cross-system analysis, automatic visualisations, and semantic understanding — deployable on infrastructure you control.
How to Get Started: From PoC to Production
The organisations that have seen the most durable results from AI agents in data engineering share a common pattern of implementation:
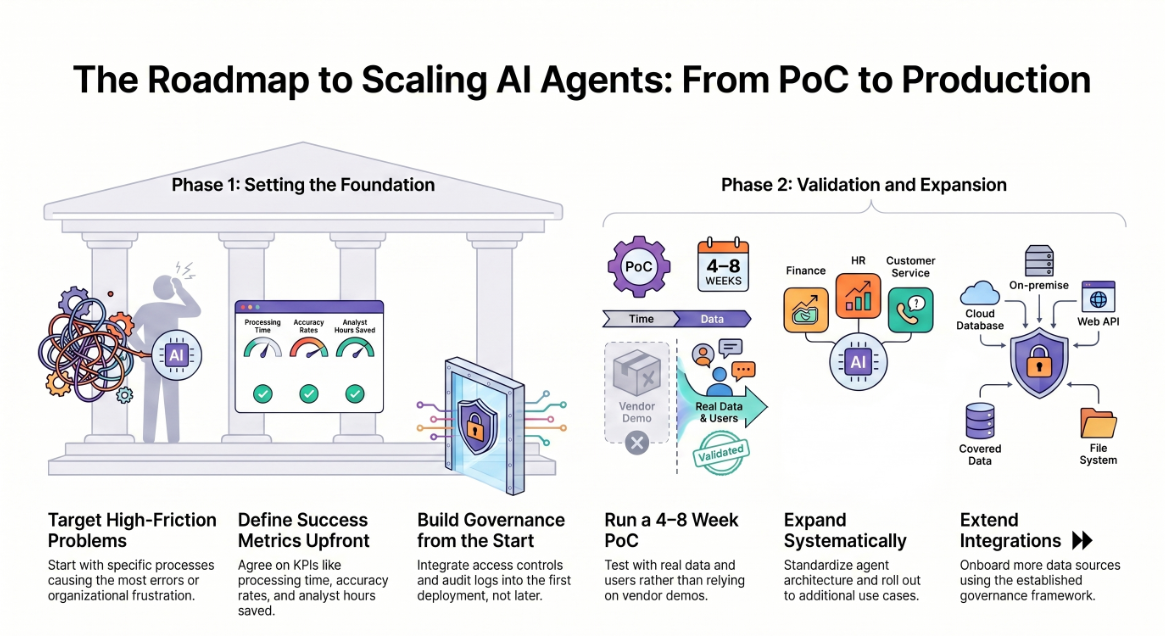
Start with a high-friction, high-value problem. Do not begin with a general "AI strategy." Begin with the specific process that is currently costing the most time, causing the most errors, or creating the most organisational frustration. Tender document processing, competitive monitoring, cross-entity reporting — these are tractable starting points with clear before/after metrics.
Define what "done" looks like before you build. Agree on success metrics upfront: processing time, accuracy rate, alert response time, analyst hours saved. This focuses the build and creates the evidence base for scaling.
Build governance in from the start. Access controls, audit logs, escalation logic, and decision rules should be built into the first deployment, not retrofitted later. The organisations that struggle with agentic AI in production are overwhelmingly those that treated governance as a later problem.
Run a 4–8 week PoC before committing to production. A well-scoped proof of concept on a real workflow — with real data, real users, and real measurement — will tell you more than any vendor demo. The best platforms will support a PoC on your environment and your data.
Expand systematically. Once a PoC has demonstrated results, the pattern for scaling is clear: standardise the agent architecture, extend integrations, onboard more data sources, and roll out to additional use cases using the same governance framework.
The organisations featured throughout this guide followed this pattern — and the outcomes they achieved reflect it.
Conclusion
AI agents in data engineering are not a future possibility. They are in production today, across industries, delivering measurable outcomes — faster processing, higher accuracy, always-on coverage, and a structural shift from reactive reporting to proactive operational intelligence.
The organisations seeing the most durable results are those that started with a specific, high-friction problem, built governance in from day one, and treated the first deployment as the foundation for a broader agentic architecture — not a one-off experiment.
If you are evaluating where AI agents could have the highest impact in your data environment, assistents.ai's Agentic Business Intelligence platform is designed exactly for this: natural language querying over your live business data, cross-system analysis, governed access, semantic understanding, and deployment on infrastructure you control.
Request a demo to see how it works in an environment like yours.
FAQs
What is an AI agent in data engineering?
An AI agent in data engineering is an autonomous system that can perceive data from its environment, reason over it, and take action — such as triggering an alert, executing a query, routing a workflow, or generating a report — without requiring a human to issue step-by-step instructions for each task.
How do AI agents automate data pipelines?
AI agents monitor pipeline behaviour continuously, detect anomalies or failures, determine the appropriate response (alert, reroute, self-correct, escalate), and take action — all without manual intervention. They can also handle ingestion from variable or unstructured sources that would break traditional fixed-schema pipelines.
What is the difference between AI agents and RPA in data workflows?
RPA automates fixed, rule-based sequences of actions and is brittle when inputs or processes change. AI agents can handle variability, reason over context, and adapt their behaviour based on what they observe — making them suitable for the messy, variable reality of most enterprise data environments.
Can AI agents replace data engineers?
No — and that is not the right framing. AI agents automate the repetitive, reactive, and rules-based elements of data engineering work, freeing engineers to focus on architecture, strategy, and the higher-order problems that require human judgment. Teams using AI agents typically see expanded output per engineer, not reduced headcount.
What tasks can AI agents perform in data teams?
Pipeline monitoring and anomaly detection, ETL and data ingestion, natural language querying, cross-system analytics consolidation, competitive monitoring, document extraction, inventory intelligence, supply chain visibility, financial workflow automation, insights-to-action triggering, and research automation — among others.
What ROI do AI agents deliver for data teams?
Organisations in production deployments report faster pipeline development (40%+ in some cases), significant reduction in data quality incidents (70%+ in some cases), and structural shifts from reactive to proactive data operations. The most consistent return is the conversion of analyst and engineer time from maintenance to strategy.
How do I get started with AI agents for data engineering?
Start with a high-friction, high-value process — one where the current approach is clearly costing time or creating errors. Define success metrics before building. Build governance in from the start. Run a 4–8 week proof of concept on real data before committing to production. Then expand using the same architecture.
What does agentic business intelligence mean?
Agentic business intelligence means the BI layer can take action, not just display information. Instead of a dashboard that a human must look at and then decide what to do, an agentic BI system detects the signal, reasons about its significance, and triggers the appropriate next step — alert, report, task, or escalation — automatically.


